
Cette page présente une lecture statistique et agrégée de la descendance issue de François Agneray et de Jeanne Evrard, fondée sur les données généalogiques actuellement accessibles.
Elle ne se substitue pas à la présentation des branches familiales ni aux pages de descendance individuelles.
Son objectif est de fournir des repères globaux, permettant de situer l’ampleur, la structure et les grandes caractéristiques de la descendance, sans publication nominative.
Périmètre et sources des données
Les statistiques présentées sur cette page sont établies exclusivement à partir du fichier GEDCOM constituant la base généalogique Agneray, telle qu’elle est exploitée sur la plateforme Geneanet. Les statistiques présentées sont donc directement dépendantes de l’état de cette base généalogique à la date de leur extraction.
Ce fichier est le résultat de nombreuses années de recherches personnelles, fondées sur le dépouillement systématique des archives paroissiales et d’état civil, complété par l’analyse et la confrontation des sources disponibles.
Aucune donnée issue de bases extérieures, de relevés collaboratifs non vérifiés ou de compilations automatiques n’a été intégrée à ces statistiques.
Les résultats présentés reflètent donc l’état précis de cette base généalogique, avec ses forces documentaires et ses limites assumées.
Taille du corpus et structure générale
La taille et la structure générale de la descendance Agneray sont présentées à partir des données agrégées issues du fichier GEDCOM, analysées à l’aide du logiciel Gedcom Studio.
Cette première lecture permet de situer l’ampleur du corpus, sans entrer dans le détail des branches ou des individus.
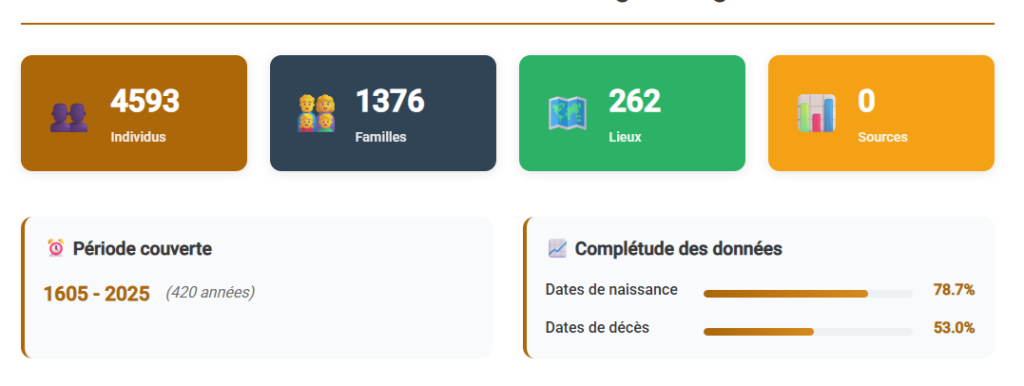
Le corpus statistique comprend :
- 4 593 individus distincts,
- 1 376 familles identifiées,
- une période couverte allant du début du XVIIᵉ siècle jusqu’au XXIᵉ siècle,
- 262 lieux distincts mentionnés dans les données.
Ces chiffres correspondent à des individus réels et distincts, et non au nombre total d’entrées généalogiques. Ils résultent d’un travail de consolidation tenant compte des implexes, c’est-à-dire de la réapparition d’un même individu dans plusieurs branches de l’arbre.
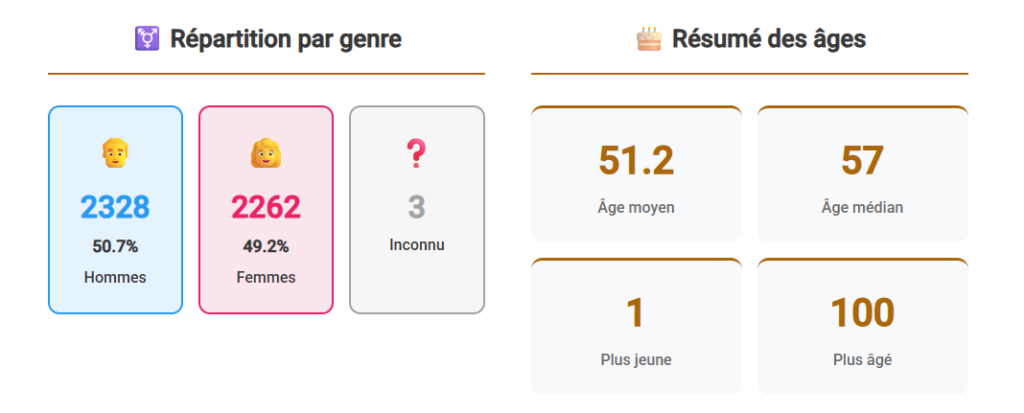
La structure du corpus montre également :
- une répartition hommes / femmes globalement équilibrée,
- un niveau de complétude variable selon les périodes,
- une diminution marquée des données disponibles à partir du XXᵉ siècle, liée à l’inaccessibilité des sources contemporaines.
La synthèse visuelle ci-dessous permet d’appréhender immédiatement l’échelle et la structure générale de la descendance.
Répartition chronologique par siècle
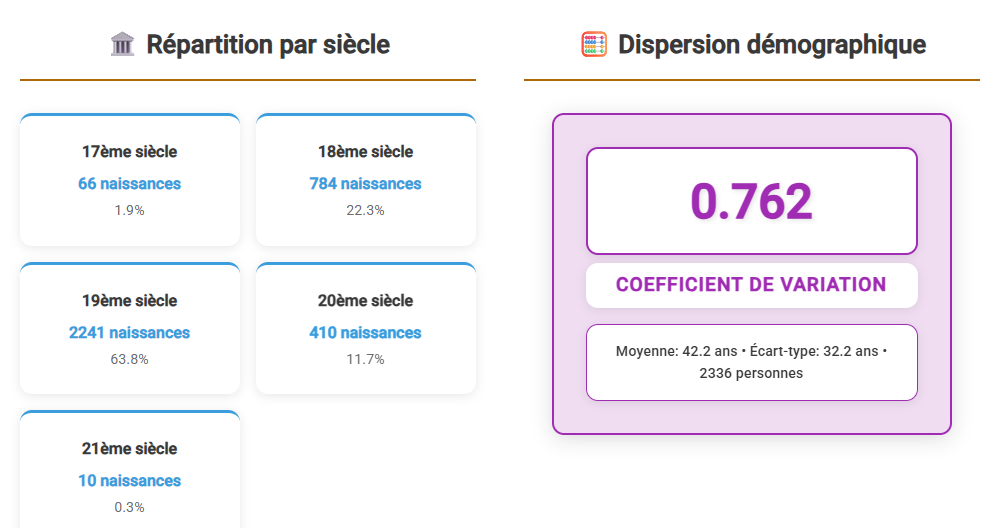
La répartition des individus par siècle permet d’appréhender la structure chronologique de la descendance Agneray, telle qu’elle ressort des données actuellement documentées dans le fichier GEDCOM.
Cette répartition est présentée sous forme graphique ci-dessous.
Les effectifs observés montrent une forte inégalité entre les siècles, avec :
- des effectifs limités pour les XVIIᵉ et début XVIIIᵉ siècles, correspondant aux générations fondatrices ;
- une représentation très majoritaire du XIXᵉ siècle, période pour laquelle l’état civil est continu et largement accessible ;
- une diminution marquée des données à partir du XXᵉ siècle.
Cette distribution doit être lue comme le reflet de l’état des sources, et non comme une image fidèle de la réalité démographique.
Les données relatives aux périodes récentes sont en effet très incomplètes, en raison de l’inaccessibilité de nombreuses archives contemporaines et des limites liées à la diffusion des informations personnelles.
La visualisation ci-dessous permet de situer immédiatement le poids documentaire respectif de chaque siècle dans la descendance étudiée.
Longévité et âges au décès
L’analyse de la longévité repose exclusivement sur les individus pour lesquels une date de naissance et une date de décès sont renseignées dans le fichier GEDCOM. Les statistiques présentées sont issues du traitement des données par Gedcom Studio.
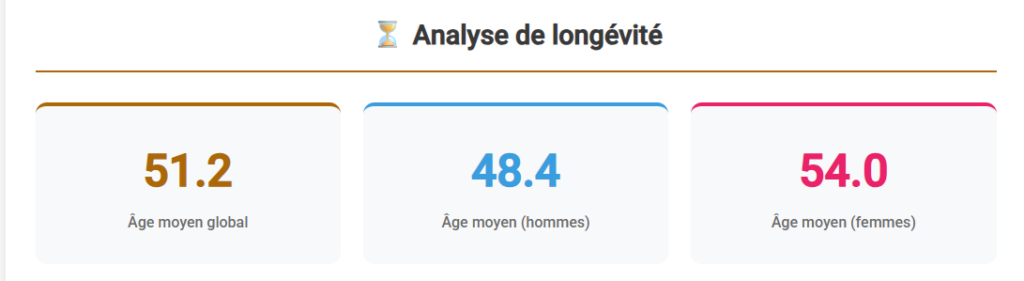
Les indicateurs globaux montrent :
- un âge moyen au décès situé autour de la cinquantaine ;
- une différence nette entre hommes et femmes, ces dernières présentant un âge moyen au décès plus élevé ;
- une dispersion importante des âges, traduisant une forte hétérogénéité des trajectoires individuelles.
Plusieurs cas de longévité élevée sont documentés, dont des individus ayant atteint ou dépassé l’âge de 100 ans. Ces valeurs correspondent à des situations individuelles précisément renseignées dans les sources.
Ces données doivent être interprétées avec prudence. Elles ne constituent ni une mesure de l’espérance de vie, ni un indicateur comparable aux statistiques nationales. Elles sont fortement dépendantes :
- de la complétude des actes de décès,
- de la surreprésentation des périodes les mieux documentées,
- et de l’absence de données fiables pour une partie des générations récentes.
Les visualisations ci-dessous illustrent les bornes et la dispersion des âges observés dans le corpus documenté.

Structure des familles et nombre d’enfants
L’analyse de la structure familiale repose sur les familles identifiées dans le fichier GEDCOM, traitées à l’aide du logiciel Gedcom Studio. Elle prend en compte le nombre d’enfants documentés par famille, toutes périodes confondues.
Les données montrent :
- un nombre moyen d’enfants par famille relativement modéré à l’échelle globale ;
- une forte majorité de familles comptant un nombre limité d’enfants ;
- l’existence de familles très nombreuses, avec des fratries atteignant ou dépassant une dizaine d’enfants.
Les familles les plus nombreuses constituent une minorité statistique, bien qu’elles soient particulièrement visibles dans les classements par valeurs maximales.
Il convient de rappeler que le nombre d’enfants indiqué correspond au nombre d’enfants effectivement documentés dans les sources. Ce chiffre peut être inférieur à la réalité historique, en raison :
- des lacunes des registres anciens,
- de la sous-déclaration des décès infantiles,
- des filiations incomplètes pour certaines périodes.
Les visualisations ci-dessous permettent d’observer à la fois les valeurs extrêmes et la distribution globale du nombre d’enfants par famille.
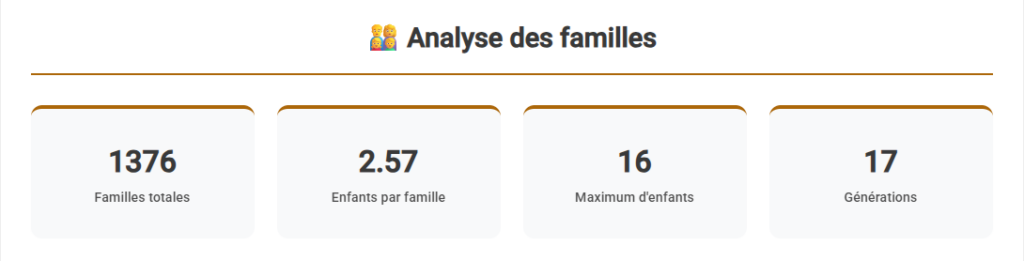
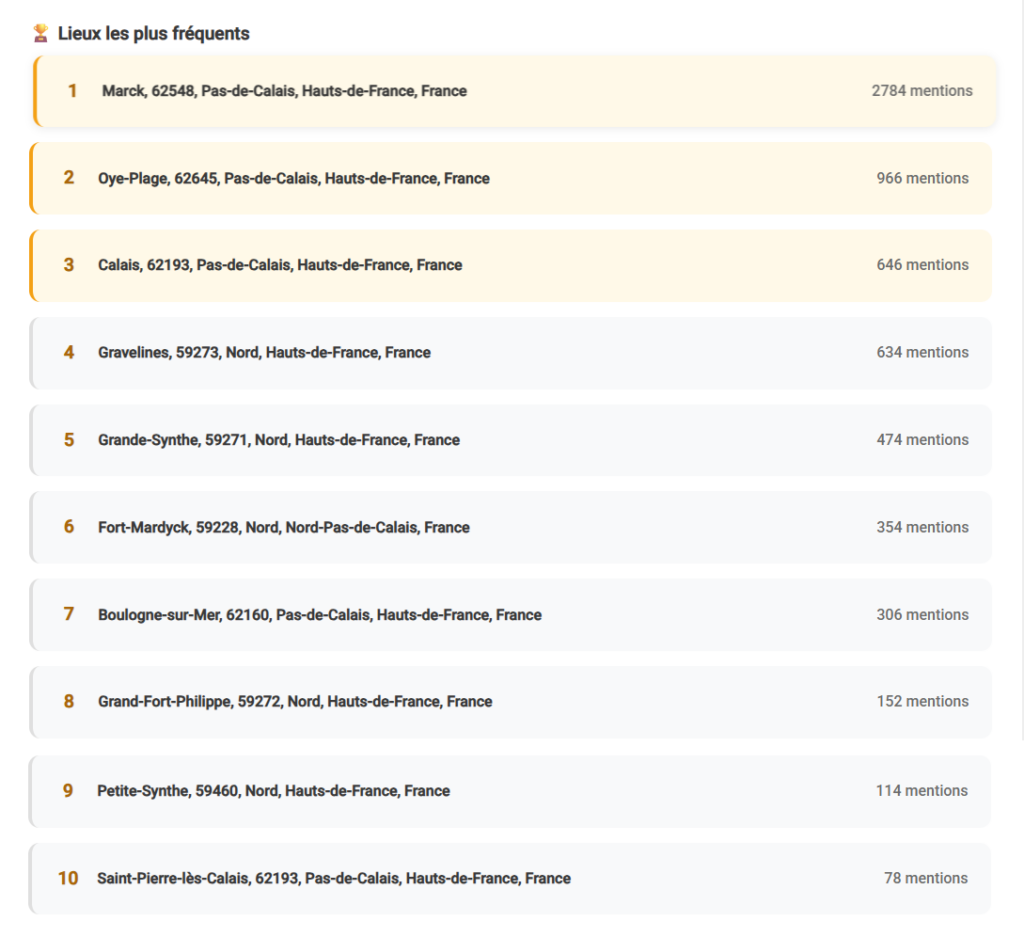
Analyse géographique de la descendance
L’analyse géographique de la descendance Agneray repose sur les lieux renseignés dans le fichier GEDCOM, tels qu’ils apparaissent dans les actes disponibles (naissances, mariages, décès), et traités à l’aide du logiciel Gedcom Studio.
Les données mettent en évidence :
- un noyau géographique fortement dominant, correspondant au Calaisis et à son littoral ;
- une dispersion progressive de la descendance au fil des générations ;
- un nombre élevé de lieux distincts, mais avec des effectifs très inégaux selon les communes.
Quelques villes concentrent une part importante des individus documentés, tandis qu’une majorité de lieux n’apparaît qu’avec un nombre très limité de personnes. Cette hiérarchie spatiale est visible à différentes échelles : globale, régionale et communale.
Il est important de souligner que cette analyse est cumulative, toutes générations confondues. Elle ne permet pas d’identifier des trajectoires individuelles, ni de distinguer précisément les lieux de naissance, de résidence ou de décès.
Les données relatives aux périodes récentes sont très incomplètes, en raison de l’inaccessibilité des sources contemporaines. La répartition observée reflète donc avant tout l’état de la documentation, et non la géographie réelle actuelle de la descendance.
Les visualisations ci-dessous illustrent la concentration et la dispersion géographique des individus documentés.

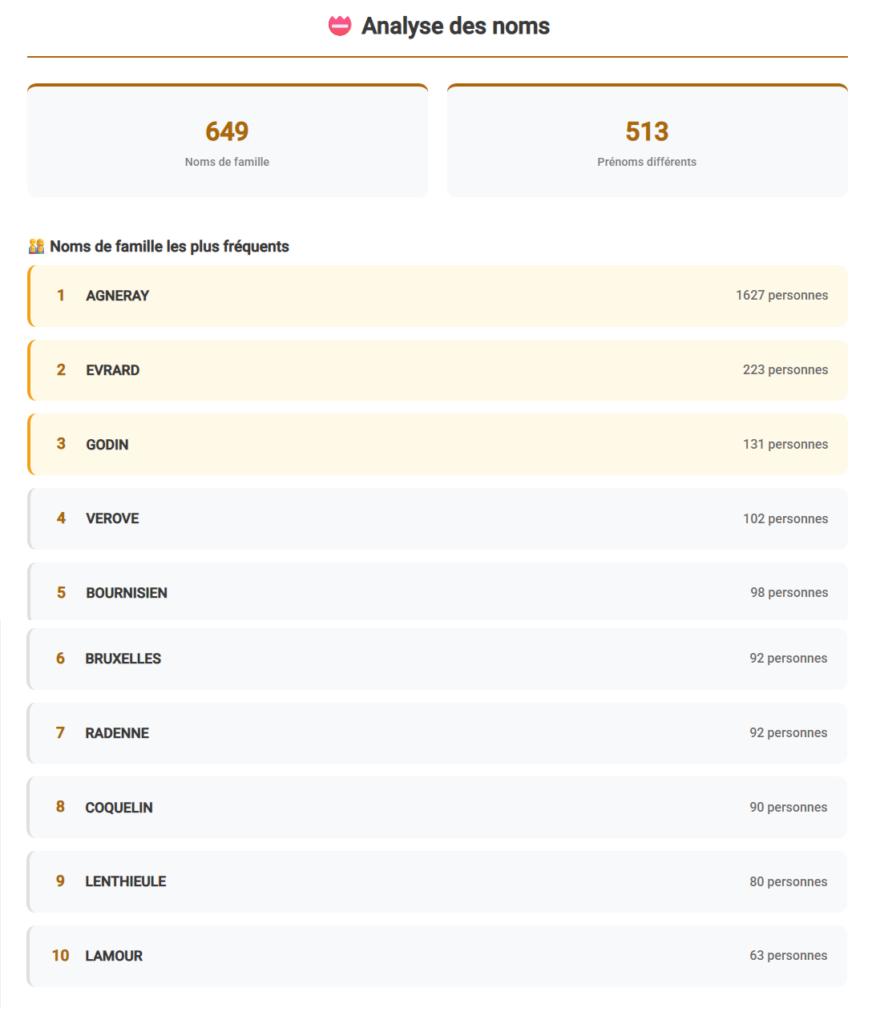
Analyse des patronymes
L’analyse des patronymes repose sur la fréquence d’apparition des noms de famille dans le fichier GEDCOM, telle qu’elle est traitée par le logiciel Gedcom Studio. Elle porte sur l’ensemble des individus documentés, toutes générations confondues.
Cette analyse met en évidence :
- la présence centrale du patronyme Agneray, transmise sur plusieurs générations ;
- l’apparition récurrente de patronymes alliés, issus des mariages et des lignées féminines ;
- une majorité de patronymes apparaissant un nombre très limité de fois dans le corpus.
Il convient de préciser que la fréquence d’un patronyme correspond au nombre d’occurrences du nom dans les données, et non au nombre d’individus distincts ni au nombre de familles. Les implexes peuvent ainsi accroître mécaniquement la visibilité de certains noms, un même individu pouvant apparaître dans plusieurs branches de l’arbre.
Cette lecture patronymique ne permet pas d’identifier des liens de consanguinité précis ni de hiérarchiser les branches familiales. Elle offre en revanche une vision d’ensemble des noms présents dans la descendance et de leur poids relatif dans le corpus documenté.
Les visualisations ci-dessous présentent la répartition et la fréquence des patronymes dans la descendance Agneray.
Implexes et parenté
Les implexes correspondent à la réapparition d’un même individu dans plusieurs branches de la descendance. Leur analyse permet d’appréhender la structure des recoupements familiaux, sans préjuger du degré de parenté canonique des unions.
Les statistiques issues du fichier GEDCOM, traitées avec Gedcom Studio, montrent que les implexes se concentrent principalement sur un nombre restreint d’ancêtres fondateurs.
L’étude de notre base a révélé un taux d’endogamie exceptionnel de 63,3%. Pour découvrir l’analyse complète de ces mariages consanguins, les patronymes les plus fréquents et nos records d’implexes, Consultez notre dossier statistique sur l’endogamie maritime ➔
L’identification du degré de parenté canonique des unions à l’origine de ces implexes relève de l’étude des actes et des dossiers de dispense, présentée dans la page consacrée aux dispenses de consanguinité. Les données statistiques se limitent ici à une observation structurelle des réapparitions, sans qualification juridique des liens.
Les implexes constituent un indicateur de l’enchevêtrement des lignées, et non une mesure directe de la consanguinité au sens canonique.